
Designing Data-Intensive Applications: Capítulo 2 - Modelos de Dados
Modelos de Dados em Aplicações Modernas: um resumo prático baseado no DDIA.

Como engenheiros de software, a maneira que escolhemos representar dados tem um impacto profundo no nosso código. Não apenas em como escrevemos, mas em como pensamos sobre os problemas que estamos resolvendo.
Hoje, vamos explorar os principais modelos de dados e suas diferenças. Vou tentar explicar de uma maneira mais prática, focando nas decisões que você precisa tomar no dia a dia.
✨ O que esperar do artigo
Os diferentes modelos de dados e quando usar cada um
Como escolher entre bancos relacionais, documentos e grafos
Dicas práticas para modelagem de dados em aplicações modernas

Modelos de Dados: Uma Visão Geral
Imagine que você está construindo uma rede social profissional, como o LinkedIn. Como você guardaria os dados de um perfil?
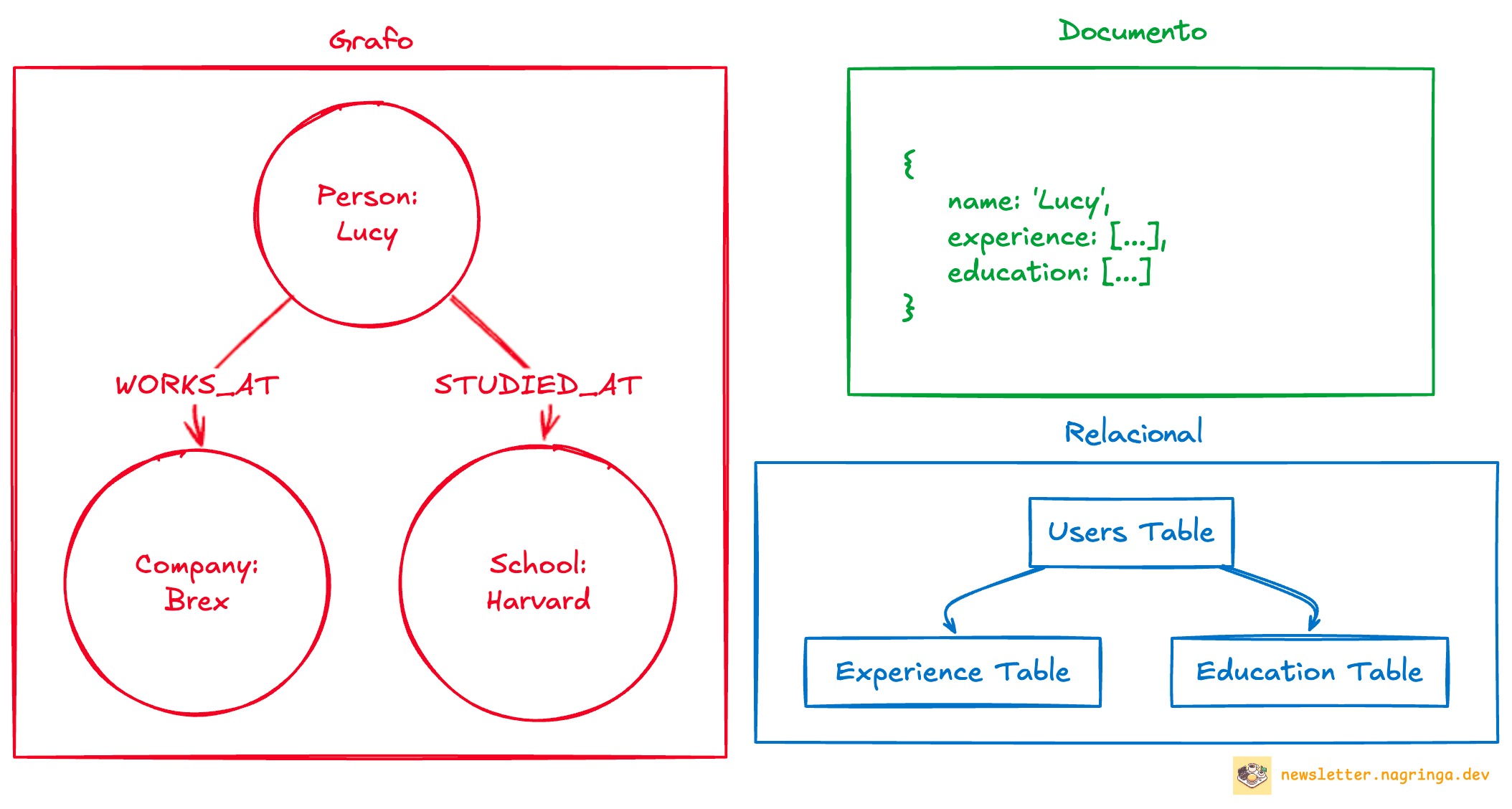
Existem três principais maneiras:
Modelo Relacional: Várias tabelas (usuários, experiências, educação) conectadas por chaves estrangeiras
Modelo de Documento: Um documento JSON com toda informação aninhada. Frequentemente chamado de banco de dados NoSQL.
Modelo de Grafo: Vértices conectados por arestas representando relacionamentos
O Modelo Relacional vs Documento (NoSQL)
Por mais de 30 anos, o modelo relacional dominou o mundo do software. Mas, com o surgimento de aplicações web modernas, novos modelos ganharam popularidade.
O segredo aqui não é escolher o modelo "vencedor", mas entender os trade-offs de cada um.
Quando usar documentos?
Documentos brilham quando seus dados tem uma estrutura natural de árvore. Exemplo: um post de blog.
{
"id": "123",
"title": "Modelagem de Dados",
"content": "...",
"author": {
"name": "Lucas Faria",
"email": "lucas@example.com"
},
"comments": [
{
"text": "Ótimo artigo!",
"author": "João"
}
]
}
Os comentários pertencem ao post. O autor pertence ao post. É uma hierarquia clara.
O modelo de documento é ideal quando você carrega todas essas informações juntas na maior parte do tempo.
Quando usar relacional?
O modelo relacional se destaca quando você tem muitos relacionamentos muitos-para-muitos. Exemplo: uma rede social.

SELECT users.name
FROM users
JOIN follows ON users.id = follows.follower_id
WHERE follows.following_id = 123;Joins são naturais em bancos relacionais. Em documentos, você precisa fazer múltiplas queries ou denormalizar dados.
Schema: Flexível ou Rígido?
Bancos de documentos são frequentemente chamados de "schemaless", mas isso não é totalmente verdade. O que muda é quando o schema é aplicado:
Schema-on-write: Em bancos relacionais, o schema é validado quando você escreve os dados
Schema-on-read: Em bancos de documentos, o schema é aplicado quando você lê os dados
É como tipagem estática vs dinâmica em linguagens de programação. Nenhuma é inerentemente melhor - depende do seu caso de uso.
Cuidados com Documentos
Documentos têm algumas limitações importantes:
Não podem ser parcialmente atualizados facilmente
Precisam ser carregados por inteiro, mesmo se você só quer uma parte
Podem ficar muito grandes e difíceis de gerenciar
O Modelo de Grafos
E quando seus dados são ainda mais conectados? É aqui que brilham os bancos de grafos.

Imagine rastrear como uma doença se espalha através de conexões sociais. Ou encontrar rotas em um mapa. Grafos tornam esse tipo de consulta muito mais natural.
// Encontrar amigos de amigos em Cypher (Neo4j)
MATCH (person)-[:FRIENDS_WITH*2]-(friend_of_friend)
WHERE person.name = "Alice"
RETURN DISTINCT friend_of_friend.nameO modelo de grafo é perfeito quando o mais importante nos seus dados são as relações entre eles.
Linguagens de Consulta
Cada modelo tem sua própria maneira de consultar dados:
SQL para bancos relacionais
MongoDB Query Language para documentos
Cypher para Neo4j
SPARQL para bancos de grafos
A grande diferença está entre linguagens declarativas (SQL) e imperativas (código tradicional).
# Imperativo (exemplo em Python)
results = []
for user in users:
if user.city == "São Paulo" and user.industry == "tech":
results.append(user)
# Declarativo (SQL)
SELECT * FROM users
WHERE city = 'São Paulo' AND industry = 'tech';Linguagens declarativas permitem que o banco otimize as consultas automaticamente.
Como Escolher um Modelo de Dados?
Aqui está um framework simples para decidir:
Use Documentos quando:
Seus dados formam uma hierarquia natural
Você geralmente carrega toda a estrutura de uma vez
Não precisa de muitas joins
Flexibilidade de schema é importante
Use Relacional quando:
Tem muitos relacionamentos muitos-para-muitos
Precisa de joins frequentes
Transações ACID são essenciais
Schema consistente é importante
Use Grafos quando:
As relações entre entidades são o mais importante
Precisa fazer consultas que atravessam múltiplas conexões
As relações tem diferentes tipos e significados
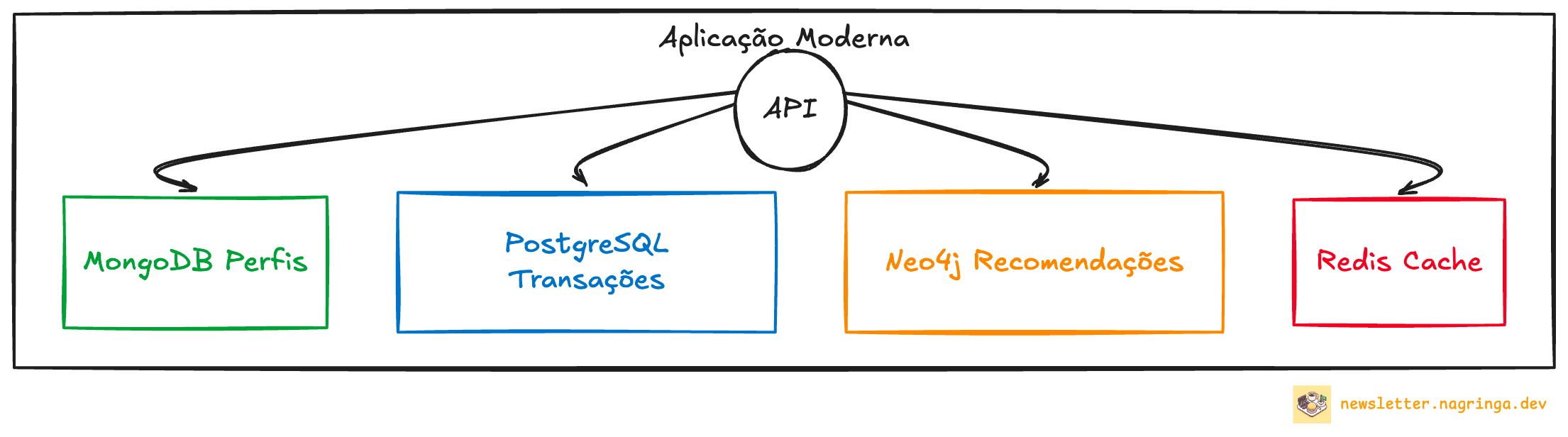
Na Prática: Polyglot Persistence
No mundo real, é comum usar diferentes modelos para diferentes partes da sua aplicação. Por exemplo:
Perfis de usuário em documentos (MongoDB, DynamoDB)
Transações em bancos relacionais (PostgreSQL, MySQL, SQLite)
Recomendações em grafos (Neo4j, AWS Neptune)
Cache em key-value stores (Redis, Memcache)
Isso é chamado de "polyglot persistence" - usar a ferramenta certa para cada trabalho.

🌟 Resumo
Não existe modelo perfeito - cada um tem seus trade-offs
Documentos são ótimos para dados hierárquicos e schema flexível
Relacional ainda é a melhor escolha para dados altamente conectados
Grafos brilham quando relacionamentos são a parte mais importante dos seus dados
É comum usar múltiplos modelos em uma mesma aplicação (polyglot persistence)
Lembre-se: o modelo de dados afeta não apenas como você guarda os dados, mas como você pensa sobre o seu domínio.
Este artigo é baseado no Capítulo 2 do livro "Designing Data-Intensive Applications" do Martin Kleppmann. Se você quer se aprofundar mais no assunto, recomendo muito a leitura do livro completo.
Muito obrigado por ser um assinante ou leitor, e ter chegado até o final!
Se você quiser fazer mais algo pra me ajudar, compartilhe esse artigo com outras pessoas e clique no botão de ❤️ curtir.