
Os 7 Padrões de System Design que Aparecem em Toda Entrevista
Tudo que eu aprendi fazendo entrevistas de System Design nos últimos 4 anos

Quase todos problema de System Design que você vai encontrar em entrevistas se resume a 7 padrões. Não importa se é WhatsApp, Uber, ou YouTube. Os mesmos problemas aparecem, as mesmas soluções funcionam.

Sobre este artigo: Este é um dos nossos artigos mais longos. A ideia é que seja uma referência completa que você pode consultar antes de entrevistas. Não precisa ler tudo de uma vez. Escolha um padrão, estude, pratique. Volte quando precisar de outro.
Retrospectiva salarial: 5 anos trabalhando remoto
O artigo dessa semana é patrocinado pela TechFX.
Meu salário cresceu 30x de 2020 a 2025. De R$2.200 da bolsa de mestrado para R$60k+.
As mudanças que fizeram diferença:
Mudei de mercado, não só de empresa. Tier 1 BR paga R$12k. Tier 3 internacional paga R$40k+. Mesmo trabalho, mercado diferente.
Negociei todo ano. No Brasil, 5-10% é “bom aumento”. Lá fora é parecido, porém, esses 5-10% você acaba sentindo muito mais (pois é em dólar).
Otimizei recebimentos. Payoneer me custava R$510/mês em taxas. TechFX custa R$135/mês. Diferença de R$4.500/ano que fica comigo.
Trabalhar remoto não garante salário alto. Mas te dá acesso a um mercado onde seu trabalho vale mais.
Conheça a TechFX e faça seu primeiro saque pagando apenas 0,1% de taxa.
Como eu cheguei aqui
Em 2021, fiz minha primeira entrevista de System Design. Falhei.
Achei que nunca ia conseguir passar nessa etapa. Parecia que todo mundo sabia coisas que eu não sabia, tinha experiências que eu não tinha.
Mas eu queria entrar em uma empresa melhor. Então comecei a estudar de verdade: ler engineering blogs, entender como sistemas reais funcionavam, praticar deliberadamente.
Com o tempo, System Design virou a etapa técnica que mais aparecia nos meus processos seletivos. Comecei como fraqueza, mas fui melhorando com prática e orientação de quem já tinha passado por isso.
Ano passado, passei como Senior Engineer no PostHog depois de uma das entrevistas de System Design mais difíceis (e mais divertidas) que já fiz.
A diferença não foi que eu fiquei mais inteligente. Foi que aprendi a reconhecer padrões.
E são sempre os mesmos 7 padrões.
Os 7 padrões
1. Scaling Reads
O problema: A maioria dos sistemas tem muito mais leituras do que escritas. Um post no Instagram é escrito uma vez, mas lido milhões de vezes. Uma URL encurtada é criada uma vez, mas redirecionada milhares de vezes por dia.
Quando você tem 100 leituras para cada escrita, seu banco de dados pode virar o gargalo. Mas antes de sair adicionando camadas de infraestrutura, entenda: bancos de dados modernos são bem mais capazes do que muita gente assume. A solução certa depende de onde está o gargalo.
A solução tem uma progressão natural. Comece pelo mais simples:

1. Otimize o banco que você já tem
Antes de pensar em cache ou réplicas, garanta que seu banco está sendo usado corretamente. Parece básico, mas é o erro mais comum que eu vejo.
Índices corretos: A diferença entre uma query com e sem índice pode ser de 500ms vs 2ms. Um SELECT * FROM urls WHERE short_code = 'abc123' sem índice faz full table scan. Com índice, é um B-tree lookup instantâneo.
Connection pooling: Cada nova conexão ao PostgreSQL custa ~5-10ms e consome memória. Sem connection pooling, sua aplicação abre e fecha conexões a cada request. Com PgBouncer na frente, você reutiliza conexões e pode multiplicar o throughput por 5-10x sem mudar mais nada.
Números reais: Um PostgreSQL bem configurado, com índices corretos e connection pooling, consegue 50-100k+ queries simples por segundo em hardware moderno. Isso é muito mais do que a maioria dos sistemas precisa. Não subestime seu banco.
2. Read Replicas: Múltiplas cópias do banco para leitura
Se um banco otimizado não aguenta, multiplique. O banco primário recebe todas as escritas e replica para bancos secundários. Leituras são distribuídas entre as réplicas.
Escritas → Banco Primário → Replica para → Banco Secundário 1
→ Banco Secundário 2
→ Banco Secundário 3
Leituras → Distribuídas entre todas as réplicasNúmeros reais: 3 réplicas = ~4x a capacidade de leitura (primário + 3 réplicas). Para a maioria dos sistemas, incluindo muitos com milhões de usuários, isso é suficiente. Cada réplica faz as mesmas queries com a mesma eficiência do primário.
Trade-off: Replicação leva tempo (milissegundos a segundos). Você pode ler dados que ainda não refletem a última escrita. Isso é eventual consistency. Para um feed do Instagram, aceitável. Para saldo bancário, não.
Quando réplicas são suficientes: Quando suas queries são simples (key lookups, filtros indexados), o tráfego é distribuído de forma razoável entre os registros, e latência de 5-20ms é aceitável. Isso cobre a grande maioria das aplicações.
3. Cache externo: Para hot spots e queries caras
Réplicas multiplicam capacidade, mas não resolvem tudo. Cache externo (Redis, Memcached) resolve problemas que réplicas não conseguem:
Hot spots: O perfil de uma celebridade no Instagram é lido 50.000 vezes por segundo. Não importa quantas réplicas você tenha. Todas estão servindo a mesma query para o mesmo registro. Cache absorve essa duplicação. Uma única entrada no Redis serve todos esses requests sem tocar no banco.
Queries caras: Se o resultado exige joins de 5 tabelas ou agregações pesadas, cada execução custa CPU significativa. Réplicas fazem o mesmo trabalho caro, só que em máquinas diferentes. Cache guarda o resultado computado e evita refazer o trabalho.
Latência sub-milissegundo: Quando 5-10ms de uma réplica não é rápido o suficiente (real-time bidding, trading, gaming) Redis entrega em <1ms.
Estruturas de dados específicas: Leaderboards (sorted sets), rate limiting (contadores atômicos), contagem de únicos (HyperLogLog). Nesses casos, Redis não é “cache”. É a ferramenta certa para o tipo de dado.
O padrão mais comum é cache-aside:
1. Cliente pede dados
2. Aplicação verifica se está no cache (Redis)
3. Se sim (cache hit): retorna em <1ms
4. Se não (cache miss): busca no banco, guarda no cache, retornaNúmeros reais: Redis aguenta ~100-500k operações/segundo com latência sub-milissegundo. Mas o valor real não é só velocidade bruta. É evitar trabalho repetido no banco.
O desafio é invalidação. Quando o dado muda no banco, o cache fica desatualizado. Estratégias:
TTL (Time-to-Live): Cache expira após X segundos. Simples, mas dados podem ficar stale.
Write-through: Atualiza cache junto com o banco. Consistente, mas adiciona latência na escrita.
Invalidação explícita: Deleta do cache quando atualiza o banco. Preciso, mas requer coordenação.
4. CDN: Cache na borda para conteúdo estático
Para arquivos que não mudam (imagens, vídeos, CSS, JS), nem cache nem réplicas são necessários. Use uma CDN.
CDN = rede de servidores distribuídos globalmente. Quando um usuário em São Paulo pede uma imagem, ela vem do servidor mais próximo, não do seu data center em Virginia.
Números reais: Sem CDN, uma imagem pode levar 200-400ms para carregar (latência de rede). Com CDN, <50ms.

Framework de decisão:
O dado é estático (não muda)?
→ Sim: CDN
O dado é dinâmico e lido muito mais do que escrito?
→ Seu banco está otimizado (índices + connection pooling)?
→ Não: Comece por aí. Sério, isso resolve muita coisa.
→ Sim, mas não aguenta o volume:
→ Adicione read replicas.
→ Ainda não é suficiente? Tem hot spots ou queries caras?
→ Sim: Agora sim, cache externo (Redis).
Não é read-heavy?
→ Talvez você tenha um problema de writes, não reads.
Na entrevista (URL Shortener):
“URLs encurtadas têm um padrão de acesso muito específico: são escritas uma vez e lidas milhares de vezes. A relação read/write é provavelmente 1000:1.
Primeiro, a query de resolução é um key lookup simples —
short_codecom índice único. Com connection pooling, um PostgreSQL aguenta isso facilmente para volumes moderados.Mas URLs populares criam hot spots: uma URL viral pode ser acessada milhares de vezes por segundo. Para isso, vou usar Redis como cache. Quando uma URL é criada, já guardo no Redis. Com uma TTL de 24 horas e as URLs mais populares sempre em cache, espero um hit rate de 90%+.
Com 90% hit rate, meu banco só precisa lidar com 10% do tráfego. Para o tráfego restante, read replicas garantem que o banco não seja gargalo. Isso escala para milhões de requests por dia facilmente.”
Tecnologias para mencionar: PgBouncer, pgcat (connection pooling). PostgreSQL streaming replication, MySQL replication (réplicas). Redis, Memcached (cache). CloudFront, Cloudflare (CDN).
Erros comuns:
Adicionar Redis antes de indexar o banco. Eu já vi times adicionarem uma camada inteira de cache quando um
CREATE INDEXteria resolvido em 5 minutos. Faça o básico primeiro.Cachear sem estratégia de invalidação. “Por que o usuário não vê a atualização?”
Ignorar thundering herd no cold start. Quando o cache está vazio, todo mundo bate no banco ao mesmo tempo.
Usar cache para dados críticos sem pensar em consistência. Saldo bancário desatualizado por 5 segundos pode custar dinheiro real.
2. Scaling Writes
O problema: Se escalar leituras é sobre “muita gente querendo a mesma coisa”, escalar escritas é sobre “muita gente querendo guardar coisas ao mesmo tempo.”
Pense em analytics: cada clique, cada page view precisa ser registrado. Um site com 1 milhão de usuários ativos pode gerar 100 milhões de eventos por dia. Isso é 1.157 escritas por segundo, em média. Em picos, pode ser 10x isso.
Um banco de dados relacional típico aguenta 10.000-20.000 escritas por segundo. Parece muito, mas acaba rápido quando cada interação dispara múltiplas escritas.
Quatro estratégias:
1. Sharding: Dividir dados entre múltiplos bancos
Se um banco aguenta 10k escritas/segundo, dez bancos aguentam 100k. A ideia é distribuir os dados de forma que cada banco receba uma fração do tráfego.
O segredo está na partition key, a chave que decide para qual shard o dado vai.
Boa partition key: user_id (distribuição uniforme)
Má partition key: país (Brasil e EUA sobrecarregam, Islândia fica vazia)
O desafio: Queries cross-shard. Se você precisa buscar dados de múltiplos shards (ex: “todos os posts do último mês”), cada query vira N queries. Escolha a partition key pensando em como os dados serão lidos também.
2. Filas: Buffer para absorver picos
Tráfego real não é constante. Black Friday, evento viral, horário de pico. De repente você tem 10x o volume normal.
Filas (Kafka, SQS, RabbitMQ) desacoplam quem escreve de quem processa:
Usuário → API → Fila → Workers → Banco
↓
Retorna "recebido" imediatamente
A API aceita a requisição e coloca na fila. Workers processam no ritmo que o banco aguenta. Se a fila cresce, você adiciona mais workers.
Trade-off: O dado não está no banco imediatamente. Para um like no Instagram, aceitável. Para uma transferência bancária, não.
3. Batching: Agrupar múltiplas escritas em uma
100 escritas individuais têm overhead: 100 conexões, 100 transações, 100 commits. Uma escrita com 100 registros tem overhead de uma.
Sem batching: 1000 likes = 1000 INSERTs
Com batching: Agrupa por 1 segundo, faz 1 INSERT com 1000 registros
Exemplo real: Contadores de view. Em vez de incrementar o contador a cada view, você acumula em memória por 5 segundos e faz um único UPDATE views = views + 47.
4. Agregação hierárquica para volumes extremos
Para milhões de eventos/segundo, você processa em camadas:
Edge servers (100) → cada um agrega 10k eventos/segundo
↓ envia resumo a cada segundo
Servidores regionais (10) → cada um recebe de 10 edges
↓ envia resumo a cada 10 segundos
Banco central → recebe 10 atualizações/segundo
Exemplo: YouTube view counts. 1 bilhão de views/dia = 11.500/segundo. Com agregação em 3 níveis, o banco central recebe ~100 escritas/segundo.

Framework de decisão:
Volume constante e previsível?
→ Sharding por partition key apropriada
Picos temporários (eventos, promoções)?
→ Filas para absorver bursts
Dados agregáveis (contadores, métricas)?
→ Batching + agregação
Volume extremo (milhões/segundo)?
→ Combinação: Sharding + Batching + Agregação hierárquica
Na entrevista (Analytics system, 1M events/second):
“1 milhão de eventos por segundo é sério. Isso é 86 bilhões de eventos por dia. Nenhum banco individual aguenta isso.
Minha estratégia combina três técnicas. Primeiro, uso Kafka como buffer de entrada, particionado por event_type.
Segundo, workers consomem do Kafka e fazem batching. Em vez de uma escrita por evento, agrupam por 1 segundo e fazem escritas em batch. Isso reduz 1 milhão de escritas para ~1.000 batch writes por segundo.
Terceiro, o banco é sharded por timestamp e event_type. Analytics geralmente consulta por período, então essa partition key otimiza tanto escritas quanto leituras.”
Tecnologias para mencionar: Kafka, SQS, RabbitMQ (filas). Cassandra, ScyllaDB, ClickHouse (bancos otimizados para escrita). DynamoDB, CockroachDB, Vitess (sharding nativo).
Erros comuns:
Sharding prematuro. Um PostgreSQL moderno aguenta 64TB de dados e 20k escritas/segundo. Faça as contas antes de adicionar complexidade.
Partition key com má distribuição. Cria hot shards.
Achar que fila resolve problema de capacidade. Fila só resolve picos. Se o volume médio excede a capacidade, a fila só cresce infinitamente.
3. Long-Running Tasks
O problema: HTTP tem timeout. Load balancers, proxies, browsers: todos assumem que uma requisição deveria terminar em 30-60 segundos. Se não termina, algo deu errado.
Mas algumas operações legitimamente demoram:
Transcodificar um vídeo de 1GB → 5-10 minutos
Gerar um relatório PDF com milhões de registros → 2-3 minutos
Processar upload de CSV com 100k linhas → 1-2 minutos
Rodar ML inference em batch → vários minutos
Se você tentar fazer isso de forma síncrona, o usuário vê timeout, fica frustrado, dá retry (que piora tudo).
A solução: Separe “aceitar a requisição” de “processar a requisição”.
ANTES (síncrono):
Usuário → API → [processa 5 min] → timeout
DEPOIS (assíncrono):
Usuário → API → cria job → retorna job_id (50ms)
↓
Fila → Worker → [processa 5 min] → atualiza status
O fluxo completo:
Usuário faz request: “Gere meu relatório anual”
API valida e enfileira: Cria registro no banco com status “pending”, coloca na fila, retorna job_id
Retorna imediatamente: “Seu relatório está sendo gerado. ID: abc123”
Worker processa: Puxa da fila, executa o trabalho pesado, salva resultado
Notifica conclusão: WebSocket, email, push notification, ou polling
Componentes essenciais:
Fila de Jobs: Onde as tarefas aguardam processamento. Precisa ser durável e suportar concorrência.
Workers: Processos separados que consomem da fila. Podem rodar em máquinas diferentes, escalar independentemente, usar hardware específico (GPU para vídeo, alta memória para relatórios).
Status Tracking: Tabela no banco com estado de cada job (pending → processing → completed/failed). Permite ao usuário consultar progresso.
Job Status Table:
abc123 → completed (10:00:00 → 10:00:05 → 10:05:23) → s3://...
def456 → processing (10:01:00 → 10:01:03 → ...)
ghi789 → pending (10:02:00 → aguardando)
Lidando com falhas:
Heartbeat + timeout: Worker envia “estou vivo” periodicamente. Se para de enviar, a fila assume que morreu e disponibiliza o job para outro worker.
Retries com backoff: Primeira tentativa falha → espera 1s → retry. Segunda falha → espera 4s. Terceira → espera 16s.
Dead Letter Queue (DLQ): Depois de N falhas (geralmente 3-5), o job vai para uma fila separada. Jobs na DLQ precisam de investigação humana.
Idempotência: O job precisa ser seguro para re-executar. Se você envia email no job, primeiro verifica se já enviou.
Framework de decisão:
A operação demora mais de 30 segundos?
→ Sim: Async workers obrigatório
A operação usa recursos diferentes (GPU, alta memória)?
→ Sim: Async workers para separar infraestrutura
O usuário precisa esperar o resultado para continuar?
→ Sim: Polling com progress updates
→ Não: Notificação quando pronto (email, push)
Na entrevista (YouTube video upload):
“Upload de vídeo tem duas fases bem diferentes: receber o arquivo e processá-lo.
Para receber, uso presigned URL direto para S3. O cliente faz upload sem passar pela minha API. Quando o upload completa, S3 dispara um evento.
Esse evento vai para uma fila. Workers de transcoding puxam jobs e geram múltiplas resoluções: 1080p, 720p, 480p, 360p. Cada resolução é um job separado que pode processar em paralelo.
O usuário vê ‘Processando...’ com barra de progresso. Consulto o status de cada job e mostro progresso agregado. Quando todos completam, o vídeo fica disponível.
Para workers, uso instâncias com GPU (para encoding rápido). Escalo baseado no tamanho da fila: se queue depth passa de 100 jobs, adiciono workers automaticamente. Falhas são tratadas com retry + DLQ.”
Tecnologias para mencionar: Kafka, SQS, RabbitMQ, Redis + BullMQ (filas). Lambda, Cloud Functions, Kubernetes Jobs (workers). Temporal, AWS Step Functions (orquestração).
Erros comuns:
“Vou só aumentar o timeout para 10 minutos.” Conexões morrem, browsers fecham, load balancers reclamam.
Status tracking como algo secundário. O usuário PRECISA saber o que está acontecendo.
Fila única para jobs de 5s e jobs de 5min. Jobs rápidos ficam presos atrás de jobs lentos. Use filas separadas.
4. Real-time Updates
O problema: HTTP é request-response: o cliente pergunta, o servidor responde, a conexão fecha. Funciona perfeitamente para a maioria da web.
Mas e quando o servidor precisa avisar o cliente de algo que aconteceu? Quando um amigo manda uma mensagem no WhatsApp, você não fica fazendo refresh a cada segundo. A mensagem simplesmente aparece.
Exemplos onde você precisa de updates em tempo real:
Chat: mensagens precisam aparecer instantaneamente
Collaborative editing: Google Docs mostra o cursor de outros usuários
Live dashboards: métricas atualizando continuamente
Notificações: likes, comentários, menções
Preços de ações: updates a cada segundo
O problema fundamental: como o servidor “empurra” dados para o cliente sem o cliente pedir?
A solução tem duas partes:
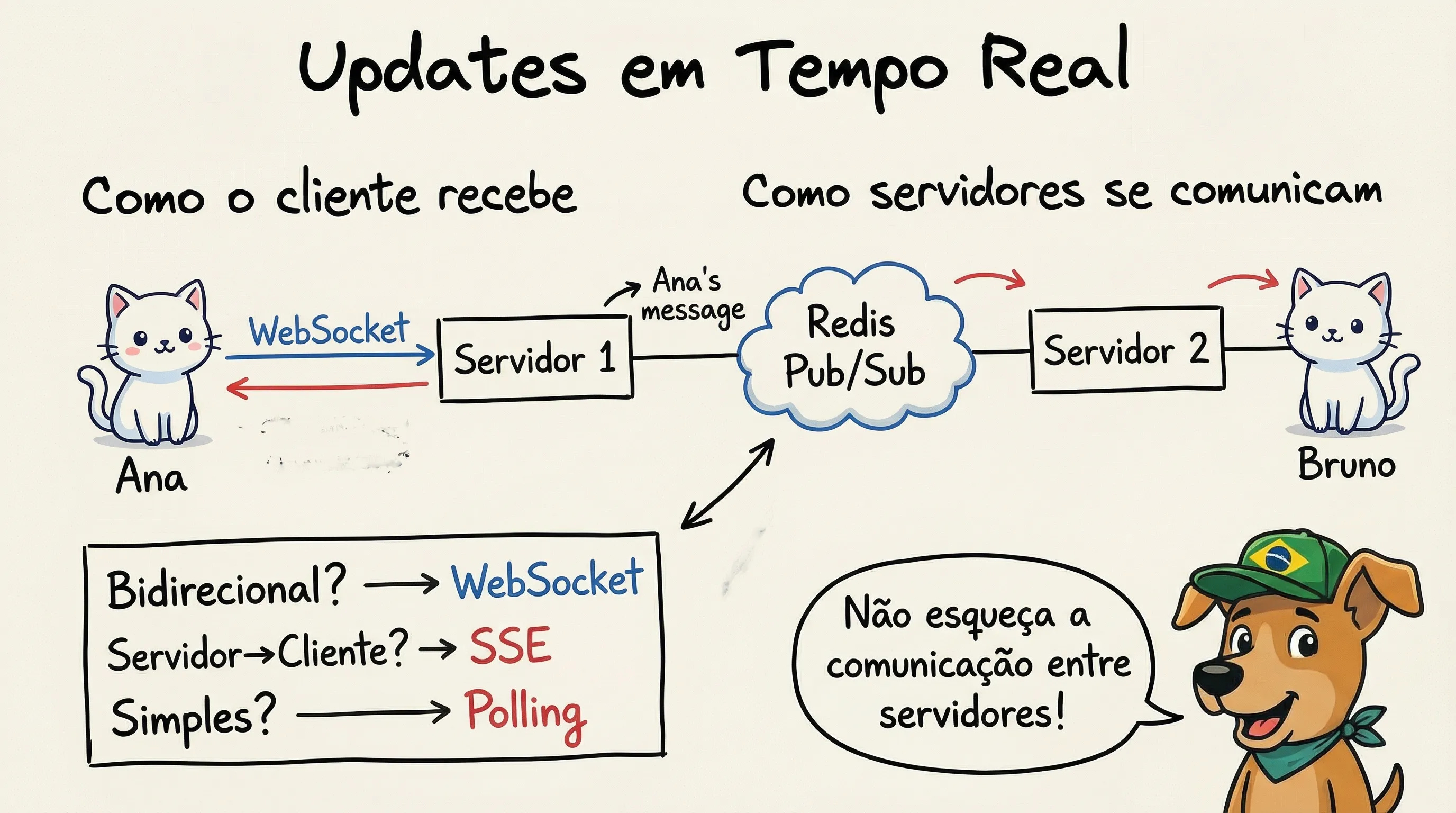
Parte 1: Como o cliente recebe (Servidor → Cliente)
1. Polling: Cliente pergunta a cada X segundos.
// Gringo fica perguntando "chegou mensagem?" a cada 2 segundos
// Mesmo quando ninguém mandou nada
setInterval(async () => {
const mensagens = await fetch('/api/mensagens/novas');
if (mensagens.length > 0) {
atualizarChat(mensagens);
}
}, 2000);
Simples, mas desperdiça requisições quando não há nada novo. Latência de até X segundos.
2. Long polling: Servidor segura a requisição até ter algo novo. Se não tiver, segura a conexão aberta por até 30 segundos.
Mais responsivo que polling, mas ainda tem overhead de criar nova conexão a cada update.
3. SSE (Server-Sent Events): Conexão HTTP permanece aberta. Servidor envia dados como “chunks” quando quiser.
// Servidor avisa Gringo quando tem novidade
// Gringo só escuta, não precisa ficar perguntando
const stream = new EventSource('/api/notificacoes');
stream.onmessage = (evento) => {
const notificacao = JSON.parse(evento.data);
mostrarNotificacao(notificacao); // 🔔 "Você tem um novo like!"
};
Comunicação unidirecional (servidor → cliente). Ótimo quando o servidor precisa enviar muitas atualizações, cliente raramente envia dados.
4. WebSockets: Conexão bidirecional persistente. Ambos podem enviar dados a qualquer momento.
// Chat do Gringo: conexão sempre aberta
// Pode mandar e receber mensagens instantaneamente
const chat = new WebSocket('wss://chat.nagringa.dev/ws');
chat.onmessage = (evento) => {
const msg = JSON.parse(evento.data);
adicionarMensagemNoChat(msg); // Ana: "Opa, tudo bem?"
};
// Gringo responde na hora
chat.send(JSON.stringify({
tipo: 'mensagem',
texto: 'Beleza! Estudando system design 🤓'
}));
Mais complexo. Conexões persistentes precisam de infraestrutura específica (load balancers L4).
Parte 2: Como o servidor descobre (Fonte → Servidor)
O cliente está conectado ao servidor via WebSocket. Mas como o servidor sabe que tem algo novo para enviar?
Pub/Sub: Servidores se inscrevem em “tópicos” (ex: chat:room123). Quando algo é publicado no tópico, todos os servidores inscritos recebem.
Ana envia mensagem → API → Publica em "chat:room123" (Redis/Kafka)
↓
Todos os servidores inscritos recebem
↓
Cada servidor envia para seus clientes conectados
Framework de decisão:
Latência de segundos é aceitável?
→ Sim: Polling simples
Updates são frequentes mas unidirecionais (servidor → cliente)?
→ Sim: SSE
Precisa de comunicação bidirecional de alta frequência?
→ Sim: WebSockets + pub/sub
Na entrevista (WhatsApp):
“Para mensagens em tempo real, vou usar WebSockets. Quando o usuário abre o app, estabelece conexão WebSocket com um servidor.
Para entregar mensagens, uso Redis pub/sub. Cada servidor se inscreve em tópicos por user_id. Quando Ana envia mensagem para Bruno, publico no tópico
user:bruno. O servidor que tem a conexão de Bruno recebe e envia via WebSocket.Para usuários offline, as mensagens ficam em uma fila persistente. Quando Bruno conecta, o servidor puxa mensagens pendentes e entrega em batch.
Para escalar, uso load balancer L4 para WebSockets. Isso mantém conexões persistentes no mesmo servidor. Heartbeats detectam conexões mortas.”
Tecnologias para mencionar: Socket.io, ws (WebSockets). Redis Pub/Sub, Kafka (pub/sub). SSE nativo em browsers modernos.
Erros comuns:
WebSockets para tudo. Se você só precisa de updates ocasionais, polling é muito mais simples.
Ignorar a comunicação entre servidores. Candidatos explicam WebSockets mas não explicam como o servidor que recebeu a mensagem notifica o servidor que tem a conexão do destinatário.
Esquecer de usuários offline. Conexões caem. O que acontece com mensagens enviadas enquanto o usuário estava desconectado?
Load balancer errado. Load balancers L7 terminam conexões TCP. Para WebSockets, você precisa de L4.
Metade do caminho. Esses padrões são a base técnica. Mas System Design é só uma etapa do processo. No curso Empresas Tier S, mostro a jornada completa: desde encontrar vagas até negociar oferta.
5. Large Files
O problema: Para arquivos pequenos, passar pelo servidor funciona. Mas para vídeos de 2GB, esse fluxo não escala:
Cliente envia 2GB para o seu servidor
Seu servidor recebe tudo (consome CPU, memória, conexões)
Seu servidor reenvia 2GB para o S3
Upload falha em 99%? Usuário recomeça do zero
Seus servidores viram intermediários. Não agregam valor, só movem bytes. E você paga banda de entrada E de saída.
A solução: Seus servidores não tocam nos bytes. Só gerenciam permissões.
Upload: Presigned URLs
Em vez de receber o arquivo, seu servidor gera uma URL temporária que permite upload direto para S3.
1. Cliente pede permissão para upload
2. Servidor valida user, gera presigned URL com validade de 15 min
3. Servidor retorna a URL
4. Cliente faz upload direto para S3 (seu servidor nunca vê os bytes)
5. S3 notifica seu servidor que upload completou (via evento)
6. Servidor atualiza status no banco
A presigned URL é uma URL normal do S3 com uma assinatura criptográfica que expira. Você pode adicionar restrições: tamanho máximo, content-type permitido.
Download: CDN com URLs assinadas
Para downloads, use CDN (CloudFront, Cloudflare). O arquivo é cacheado em servidores ao redor do mundo. Usuário em São Paulo baixa do edge server mais próximo.
Sem CDN: Usuário SP → Virginia → 200ms latência
Com CDN: Usuário SP → Edge SP → 5ms latência
URLs assinadas controlam acesso: só quem tem a URL válida consegue baixar. Expira em X horas.
Uploads grandes: Multipart/Chunked
Para arquivos de gigabytes, upload único é frágil. Se a conexão cair em 99%, perdeu tudo.
Solução: dividir em partes (5-100MB cada).
Arquivo de 500MB → 100 partes de 5MB
Parte 1 ✓
Parte 2 ✓
...
Parte 47 ✗ (conexão caiu)
→ Resume da parte 47, não do zero
S3 Multipart Upload, GCS Resumable Upload, Azure Block Blobs todos suportam isso nativamente.

Sincronização de estado:
O desafio: seu banco de dados e o S3 são sistemas separados. Como saber quando o upload realmente completou?
Confiar no cliente é arriscado. Cliente pode crashar depois do upload mas antes de notificar. Cliente malicioso pode dizer “completou” sem ter enviado.
Solução: S3 Event Notifications. S3 dispara eventos quando arquivos são criados. Configure para enviar para SQS ou Lambda. Worker recebe evento, atualiza status para “completed”.
Como rede de segurança, um job periódico verifica arquivos “pending” há mais de X horas e confirma se existem no S3.
Framework de decisão:
Arquivo maior que 10MB?
→ Sim: Upload direto com presigned URL
Arquivo maior que 100MB?
→ Sim: *Multipart upload* (resumable)
Arquivo será acessado frequentemente?
→ Sim: CDN com cache
Precisa validar conteúdo antes de aceitar?
→ Sim: Upload para bucket de quarentena, processa, move para bucket final
Na entrevista (Dropbox):
“Para uploads, vou usar presigned URLs. Quando o usuário quer fazer upload, o cliente pede permissão à API. A API valida o usuário, verifica cota de storage, e retorna uma presigned URL do S3.
Para arquivos grandes, uso S3 Multipart Upload. O cliente divide o arquivo em chunks de 10MB, faz upload de cada chunk para URLs separadas, e no final chama um endpoint de ‘complete’ que diz ao S3 para juntar os chunks.
Se a conexão cair, o cliente pode consultar quais chunks já foram enviados e resumir dali. Isso é crítico para arquivos de gigabytes.
Para sincronizar estado, S3 dispara eventos quando uploads completam. Um worker processa esses eventos e atualiza o banco de dados.
Downloads vão via CloudFront. URLs assinadas expiram em 1 hora.”
Tecnologias para mencionar: S3, Google Cloud Storage, Azure Blob Storage (object storage). CloudFront, Cloudflare, Fastly (CDN). S3 Event Notifications, Cloud Storage pub/sub (eventos).
Erros comuns:
“Vou receber o arquivo e salvar no S3.” Red flag. Seus servidores não devem ser intermediários de bytes.
Ignorar multipart para arquivos de GB. Upload único que falha = UX terrível.
Confiar cegamente no cliente. Se o cliente diz “upload completo”, verifique via S3 antes de mostrar como disponível.
6. Contention
O problema: Último ingresso para o show do Taylor Swift. Ana e Bruno clicam “Comprar” no mesmo instante.
10:00:00.000 - Ana lê: 1 ingresso disponível ✓
10:00:00.001 - Bruno lê: 1 ingresso disponível ✓
10:00:00.050 - Ana pensa: "Oba, vou comprar!"
10:00:00.051 - Bruno pensa: "Oba, vou comprar!"
10:00:00.100 - Ana compra → ingressos = 0
10:00:00.102 - Bruno compra → ingressos = -1 💀
Resultado: dois clientes pagaram pelo mesmo ingresso. Um vai ser barrado na porta.
Isso é uma race condition. O problema acontece porque existe um intervalo entre “ler o estado” e “atualizar o estado”. Nesse intervalo, outro processo pode mudar o mundo.
Quanto mais escala, pior fica. Com 10.000 usuários simultâneos competindo pelo mesmo recurso, conflitos são garantidos.
Três abordagens:
1. Pessimistic Locking: Trancar antes de ler
“Assumo que vai ter conflito, então tranco o recurso antes de qualquer coisa.”
BEGIN TRANSACTION;
-- Ana tranca o ingresso ANTES de ler
-- Bruno vai ter que esperar na fila
SELECT ingressos_disponiveis FROM shows
WHERE show_id = 'taylor-swift-sp-2025'
FOR UPDATE;
-- Só Ana pode modificar agora
UPDATE shows
SET ingressos_disponiveis = ingressos_disponiveis - 1
WHERE show_id = 'taylor-swift-sp-2025';
COMMIT;
-- Agora Bruno pode tentar (mas já era, Ana comprou)
O FOR UPDATE adquire um lock exclusivo. Bruno fica bloqueado esperando Ana terminar.
Quando usar: Alta contenção, consistência crítica. Você sabe que conflitos são prováveis.
Trade-off: Pode virar gargalo. Se todo mundo tenta trancar o mesmo recurso, forma fila.
2. Optimistic Concurrency Control (OCC): Detectar conflito depois
“Assumo que conflito é raro. Se acontecer, detecto e tento de novo.”
-- Ana e Bruno leem ao mesmo tempo: 1 ingresso disponível
-- Nenhum dos dois trancou nada (otimista!)
-- Ana tenta comprar:
UPDATE shows
SET ingressos_disponiveis = ingressos_disponiveis - 1
WHERE show_id = 'taylor-swift-sp-2025'
AND ingressos_disponiveis = 1; -- "Só se ainda tiver 1"
-- ✅ Ana: UPDATE afetou 1 linha. Comprou!
-- Bruno tenta comprar (milissegundos depois):
UPDATE shows
SET ingressos_disponiveis = ingressos_disponiveis - 1
WHERE show_id = 'taylor-swift-sp-2025'
AND ingressos_disponiveis = 1; -- "Só se ainda tiver 1"
-- ❌ Bruno: UPDATE afetou 0 linhas (agora tem 0, não 1)
-- Sistema detecta: "Ops, alguém foi mais rápido. Esgotado!"
A chave é incluir o valor esperado no WHERE. Se o valor mudou desde que você leu, o UPDATE não afeta nenhuma linha.
Quando usar: Baixa contenção, leituras frequentes. A maioria dos updates não conflita.
Trade-off: Sob alta contenção, muitos retries. Pode ser ineficiente.
3. Reservations: Acesso exclusivo temporário
“Em vez de competir no checkout, reservo o recurso antes.”
Usuário seleciona assento → Sistema cria reserva de 10 minutos
→ Outros usuários veem assento como "indisponível"
→ Usuário tem 10 min para completar pagamento
→ Se não completar, reserva expira automaticamente
Isso reduz a janela de contenção drasticamente. Em vez de competir durante todo o fluxo de pagamento (5 minutos), a competição acontece só no momento de criar a reserva (milissegundos).

Framework de decisão:
Os dados estão em um único banco?
→ Sim: Use locks ou OCC, não complique
Conflitos são frequentes (alta contenção)?
→ Sim: Pessimistic locking
→ Não: Optimistic concurrency control
É fluxo de usuário (não backend)?
→ Sim: Considere reservations para melhor UX
Na entrevista (Ticketmaster):
“O problema central aqui é contenção: milhares de pessoas competindo pelos mesmos assentos.
Vou usar um sistema de reservas. Quando o usuário clica em um assento, crio uma reserva com expiração de 10 minutos. O assento fica bloqueado para outros usuários nesse período.
Para implementar, uso um campo
reserved_untilno banco. Ao selecionar assento:UPDATE seats SET reserved_by = 'user123', reserved_until = NOW() + INTERVAL '10 minutes' WHERE seat_id = 'A15' AND (reserved_until IS NULL OR reserved_until < NOW());Se o UPDATE afeta 0 linhas, o assento já está reservado por outro.
Para a compra final, uso pessimistic locking para garantir atomicidade. Isso é aceitável porque a contenção real foi reduzida. Só quem tem reserva válida chega aqui.
Um job periódico limpa reservas expiradas.”
Tecnologias para mencionar: SELECT ... FOR UPDATE (PostgreSQL, MySQL), transações com isolation level SERIALIZABLE (locks). Version columns, conditional updates (OCC). TTL em Redis, campos reserved_until em SQL (reservations).
Erros comuns:
Ignorar race conditions. “Vou só fazer UPDATE no banco” sem pensar em concorrência é red flag.
Distributed locks para tudo. Se seus dados estão em um único banco, não precisa de Redis para locks. Transações resolvem.
Pessimistic locking com transações longas. Se você tranca uma linha e depois faz chamada externa (pagamento), você segura o lock por segundos.
7. Multi-step Processes
O problema: E-commerce: cobrar pagamento → reservar estoque → criar etiqueta de envio → enviar email de confirmação.
O que acontece se o passo 3 falha? Você já cobrou o cliente e reservou o estoque. Precisa desfazer tudo.
1. Cobrar pagamento ✓ ($500 debitados)
2. Reservar estoque ✓ (item bloqueado)
3. Criar etiqueta ✗ (serviço de shipping fora do ar)
→ E agora? Cliente foi cobrado mas não vai receber o produto
Isso é um workflow distribuído: uma sequência de passos que:
Envolve múltiplos serviços
Pode falhar em qualquer ponto
Precisa de rollback se algo der errado
Pode demorar minutos, horas, ou dias
A solução tem duas abordagens:
1. Saga Pattern: Transações com compensação
Em vez de uma grande transação distribuída, você faz uma sequência de transações locais. Cada passo tem uma “ação de compensação” que desfaz o que foi feito.
Passo 1: Cobrar pagamento
→ Compensação: Estornar pagamento
Passo 2: Reservar estoque
→ Compensação: Liberar reserva
Passo 3: Criar etiqueta
→ Compensação: Cancelar etiqueta
Passo 4: Enviar email
→ Compensação: (não precisa. Email já foi)
Se passo 3 falha:
1. Cobrar pagamento ✓
2. Reservar estoque ✓
3. Criar etiqueta ✗
→ Executar compensação do passo 2 (liberar reserva)
→ Executar compensação do passo 1 (estornar)
Trade-off: Durante a execução, o sistema está temporariamente inconsistente. Depois do passo 1, o dinheiro saiu da conta do cliente mas ele ainda não tem o produto. Isso é eventual consistency. Você aceita inconsistência temporária em troca de simplicidade.
2. Workflow Engines: Orquestração durável
Escrever sagas manualmente é propenso a erros. Workflow engines (Temporal, AWS Step Functions) fazem isso automaticamente.
// Workflow de compra do Gringo
// Se qualquer passo falhar, desfaz os anteriores
async function workflowCompraGringo(pedido) {
// Passo 1: Cobra o cartão
const pagamento = await cobrarCartao(pedido);
if (!pagamento.ok) {
return { sucesso: false, erro: "Pagamento recusado 💳" };
}
// Passo 2: Reserva o produto
const estoque = await reservarEstoque(pedido);
if (!estoque.ok) {
await estornarPagamento(pedido); // Desfaz passo 1!
return { sucesso: false, erro: "Produto esgotou 😢" };
}
// Passos 3 e 4: Finaliza
await criarEtiquetaEnvio(pedido);
await enviarEmailConfirmacao(pedido);
return { sucesso: true }; // 🎉 Gringo feliz!
}
Parece código normal, mas o engine garante:
Durabilidade: Se o servidor cair, outro continua de onde parou
Retry automático: Falhas transientes são retriadas
Estado persistido: Cada passo completado é salvo
Quando usar workflow engines:
Processos que duram mais de segundos (interações humanas, aprovações)
Coordenação complexa com muitos serviços
Necessidade de audit trail completo

Framework de decisão:
Processo é simples (2-3 passos, tudo rápido)?
→ Saga implementada manualmente
Processo é complexo ou de longa duração?
→ *Workflow engine* (Temporal, Step Functions)
Precisa esperar por humanos (aprovações, etc)?
→ *Workflow engine* com *signals*
Na entrevista (Uber ride request flow):
“O fluxo de uma corrida envolve múltiplos passos com waits: request → match driver → driver accepts → pickup → ride → complete → charge.
Vou usar um workflow engine como Temporal. O workflow principal é:
Receber request do rider
Encontrar drivers próximos
Enviar request para driver mais próximo
WAIT: driver aceita ou timeout (30s) → Se timeout, voltar ao passo 3
WAIT: driver chega ao pickup
WAIT: rider confirma que está no carro
Ride em andamento
WAIT: driver marca como completo
Calcular e cobrar tarifa
Cada ‘WAIT’ é um signal no Temporal. O workflow fica suspenso sem consumir recursos. Quando o evento chega (driver aceita, rider confirma), o workflow continua.
Compensações: se o pagamento falhar no passo 9, o ride já aconteceu. Não dá para desfazer. Nesse caso, marco como ‘payment pending’ e uso um processo separado de cobrança retry.”
Tecnologias para mencionar: Temporal, AWS Step Functions, Google Cloud Workflows (workflow engines). Apache Airflow, Prefect (data pipelines). Bull/BullMQ (opções mais simples).
Erros comuns:
Implementar saga complexa manualmente. Se você tem mais de 5 passos com compensações, use um workflow engine.
Ignorar idempotência. Se um passo falha depois de executar mas antes de confirmar, o workflow vai re-executar. Cada passo precisa ser idempotente.
Não pensar em compensações impossíveis. Nem tudo pode ser desfeito. Email enviado não volta. Ride completada não desaparece.
Juntando tudo
A maioria dos problemas de System Design são combinações desses 7 padrões.
Exemplo: “Design Instagram”
Upload de fotos → Large Files (presigned URLs)
Feed loading → Scaling Reads (cache + CDN)
Like counts → Scaling Writes (batching)
Notificações → Real-time Updates (push)
Stories expiring → Long-Running Tasks (scheduled jobs)
Exemplo: “Design Uber”
Ride matching → Multi-step Process (workflow)
Driver location updates → Scaling Writes (batching)
Rider vê driver se aproximando → Real-time Updates (WebSockets)
Múltiplos riders pedindo mesmo driver → Contention (reservations)
Histórico de corridas → Scaling Reads (cache)
Estratégia na entrevista:
Identifique o desafio central: Qual é o problema de escala ou complexidade aqui?
Mapeie para padrões: Isso é read-heavy? Write-heavy? Long-running? Competitive access?
Explique trade-offs: Não só “vou usar Redis”, mas “vou cachear com TTL de 5 min porque eventual consistency é aceitável aqui”
Quantifique quando possível: “Com 90% hit rate, o banco só precisa lidar com 10% do tráfego”
O que separa quem passa de quem não passa
Aqui está o segredo que ninguém te conta: o entrevistador já sabe a resposta. Ele não está tentando descobrir se você conhece Redis ou Kafka. Ele está avaliando como você pensa.
System Design é, tecnicamente, uma entrevista técnica. Mas na prática? É uma das entrevistas mais comportamentais que existe.
O entrevistador está avaliando:
Você faz perguntas ou assume coisas?
Você aceita feedback ou fica defensivo?
Você explica seu raciocínio ou só joga tecnologias?
Você colabora ou faz um monólogo?

Comunicação não é um diferencial. É requisito.
Se comunicação é seu ponto fraco, pratique:
Brown bags / Tech talks: Apresente algo que você aprendeu para o time
Liderar design meetings: Quando tiver uma feature nova, se voluntarie para facilitar a discussão
Escrever design docs: Documentar uma decisão técnica força você a estruturar pensamento
Gravar você mesmo: Resolva um problema de System Design em voz alta, grave, assista depois
A diferença entre eu falhando em 2021 e passando no PostHog não foi ficar mais inteligente. Foi aprender a mostrar como penso, não só o que sei.
Próximos passos
Para praticar:
Escolha 2-3 problemas clássicos (URL Shortener, WhatsApp, Uber)
Para cada um, identifique quais dos 7 padrões se aplicam
Pratique articulando a solução em voz alta
Faça mock interviews com colegas - você aprende dos dois lados
Use HelloInterview.com para feedback estruturado
E não esqueça das práticas do dia a dia que mencionei acima: design docs, tech talks, liderar discussões. Comunicação se desenvolve no trabalho, não só em simulados.
Leitura relacionada:
Guia 2025: Entrevistas Comportamentais - a etapa que mais pesa na decisão final
Design Docs e RFCs - como documentar decisões técnicas
Para ir mais fundo:
System Design é só uma etapa do processo. Se você quer a jornada completa para entrar em empresas que pagam $100k+, criei o curso Empresas Tier S.
Desde encontrar vagas até negociar oferta, com artefatos reais: as offer letters que recebi, mensagens que mandei, e feedback das minhas entrevistas.
Os 7 padrões te dão o vocabulário. A prática te dá a fluência.
Boa sorte na próxima entrevista.

Eu entrevisto uma galera na gringa e raramente chegamos a esse nível. Os manos bons estão super bem empregados, e é raro encontrar gente que chegue a 10% desse conhecimento. Mas, quando encontramos esse cavalo selado, tentamos capturar esse cara assim que possível. Depois da contratação, ele poderá usar IA à vontade e ninguém liga. Mas ainda é preciso, cada vez mais, atentar-se às decisões de arquitetura e engenharia, e saber guiar corretamente a IA.
Tudo começa com um bom teste técnico. A pessoa precisa transmitir experiência e segurança no que está fazendo. Portanto, mesmo em tempos de LLMs, continuem treinando e fazendo código sem vibe coding.
Agradeço pela alta qualidade do texto e mando abraços!
Artigo brabo demais, agradeço por criar e disponibilizar pra todos.